【论文阅读】【ASE 22'】SELFAPR:带有测试执行诊断的自监督APR
论文信息
- 题目:SelfAPR: Self-supervised Program Repair with Test Execution Diagnostics
- 链接:https://arxiv.org/abs/2203.12755
主要问题
之前基于学习的监督修复方法样本来自现有的项目源码,它们遗漏两个关键点:
- 被修复程序的应用领域。若目标的修复样本未出现在训练集中,就很难完成修复。
- 执行信息。通常情况下标签中不会带有bug的错误信息(比如空指针)。
所以本文主要依托自监督方法解决这个问题。首先扰动生成数千个训练样本,然后执行每个样本收集其错误信息。推力时使用待修复程序的失败用例错误作为诊断。
主要贡献:
- 提出原创的自监督编码和带有诊断的APR方法
- 实验
- 开源
SELFAPR
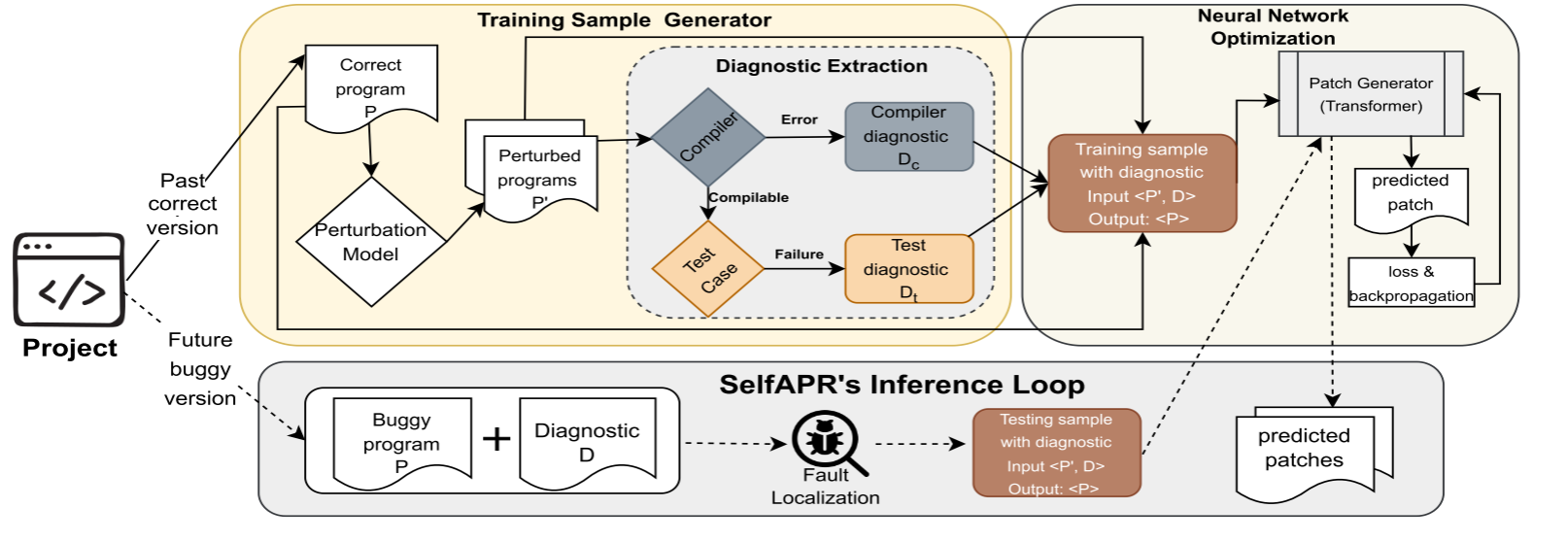
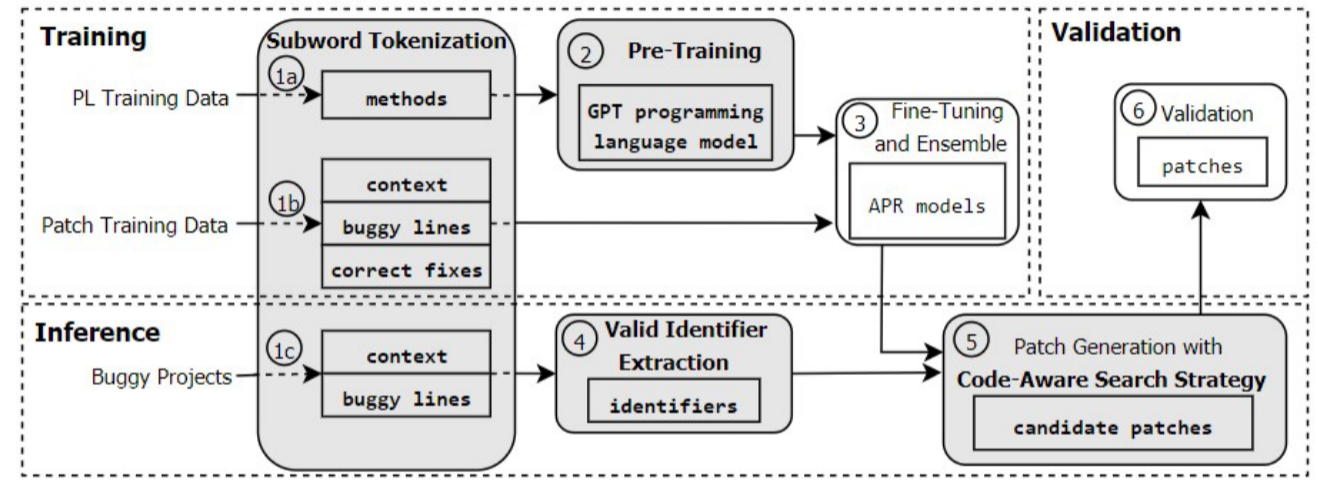
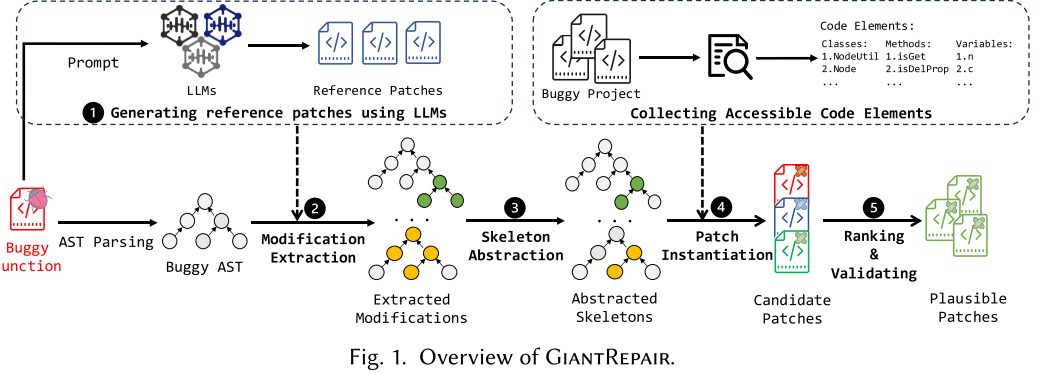
上半部分为训练过程,下半部分为推理过程。其核心是以特定于项目的自监督方式生成训练样本,错误样本则为扰动生成。其中,训练阶段由样本生成部分(左)和嵌入测试执行信息的transformer结构(右)。正确程序P的基础上生成扰动程序P’,根据所需数据集大小生成多个P’。在编译和测试执行确定错误,产生错误类型和错误诊断D。学习模型的输入为P’和D,目标为预测扰动前的期望输出P(原始代码)。推理阶段使用训练好的模型修复同一项目的未来错误,它接受一个错误程序P和错误诊断D作为输入,再用故障定位FL生成可以错误行的排名列表,对于FL发现的可以语句构造一个推理输入交给模型。模型输出最可能的补丁,枚举K个最佳。
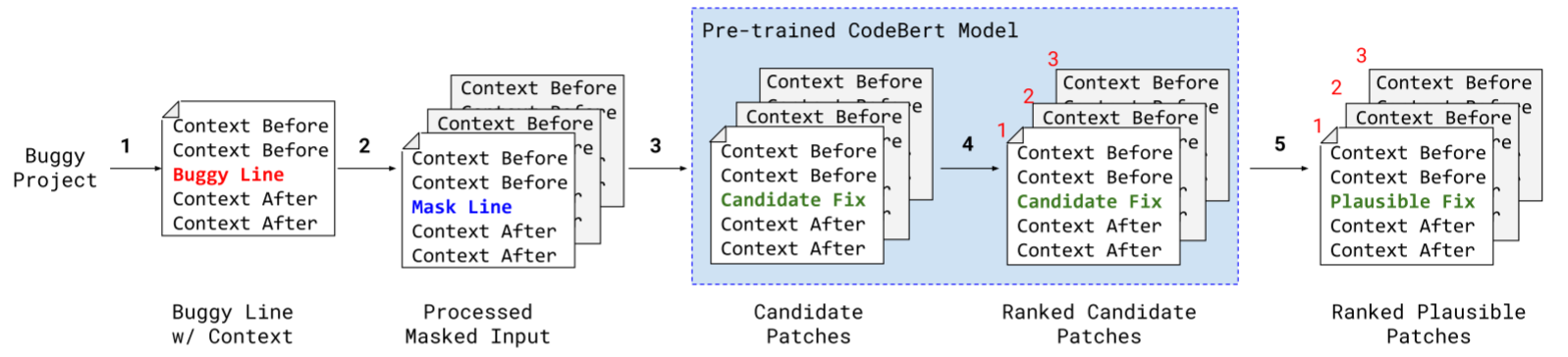
扰动模型 Perturbation Model
目的是通过正确程序生成带有错误的训练样本。指定扰动规则,例如,如果学习目标是学习如何插入语句,则扰动模型可能通过删除语句来生成训练样本;反过来,训练样本教神经模型学习插入已删除的代码。
扰动规则通常是类型、判断条件等的增删改。以下为示例:
学习目标:
- 重用同一程序中的现代码。需要重用程序修复中的代码,鼓励扰动模型重用bug附件的源代码,变现为规则中包含移除的方法鼓励字句重用。
- 根据上下文合成代码。源码的低熵特性(高上下文冗余),表现为在规则中包含根据最近上下文合成补丁。
- 学习删除。规则中包含添加多余代码。
诊断抽取
SELFAPR的每一个生成样本P’都是错误的。针对编译器和可用的套件执行之,来确定它是否是一个有效的错误样本。诊断包含编译错误和测试错误,分别引导模型关注测试套件和测试用例。
诊断为一个token序列,其tokenize的方法与源代码相同。以下是一个诊断示例:
补丁排序
约束方法进行补丁排序(束搜索),计算可能的token根据整体预测最大似然估计对输出排序。
实验
数据
Defects4j2.0,内含17个开源项目的835个真实错误组成。训练集由这些代码的扰动构成.下表为训练测试集的具体信息。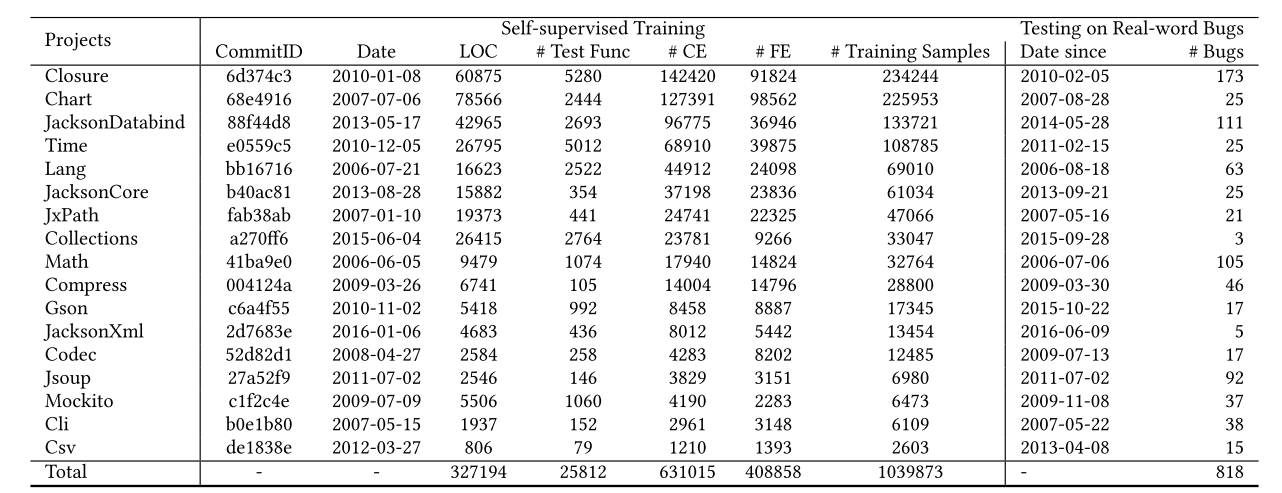
另外,文章展示了在该基准上应用12种扰动方法产生的不同结果。以下是不同扰动方法产生代码的占比情况: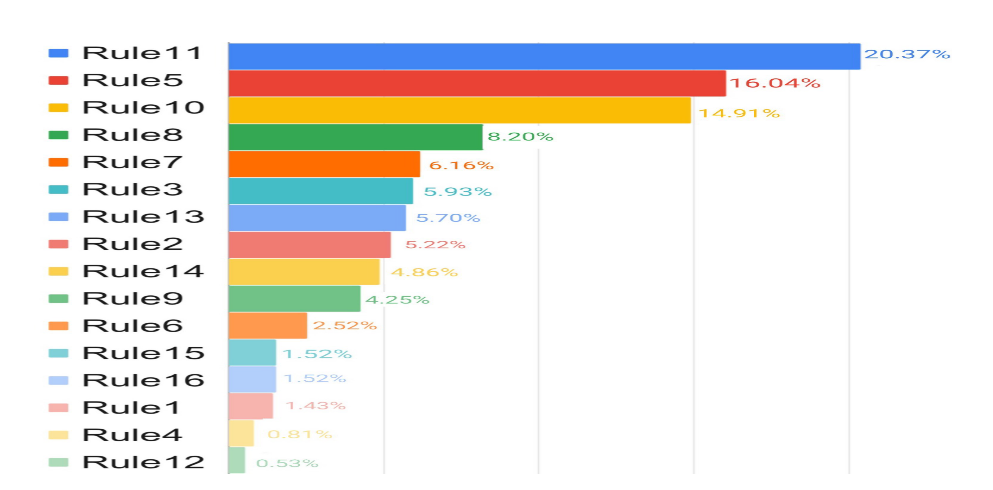
以下是扰动方法所产生的不同错误: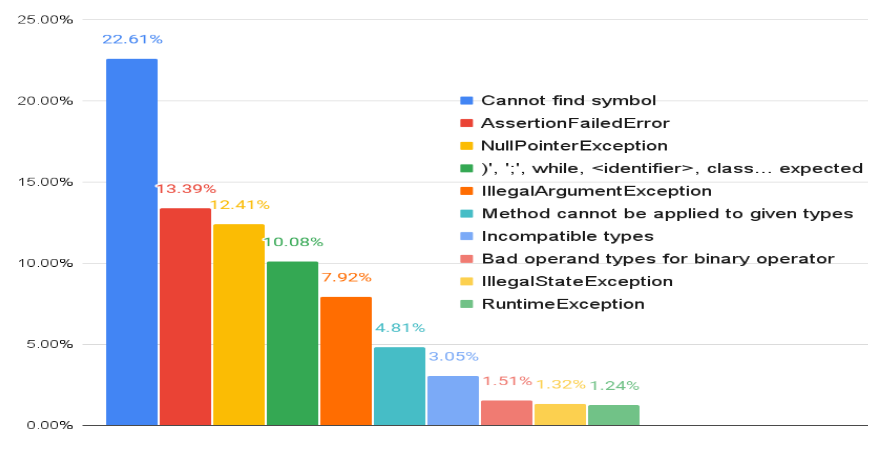
评价指标
- 正确修复的bug数量
- 根据Noller等人给出的开发者接受视角,在波束搜索算法中按波束宽度配置的正确补丁的排序信息(Trust Enhancement Issues in Program Repair)
RQ1:自我监督的有效性
下表种,第一列是baseline。第二列和第三列给出了实验设置,包括训练样本的数量和基于学习的方法的束搜索配置。第四到七列显示了在两个考虑的基准测试中,每种APR方法的正确补丁和合理补丁的数量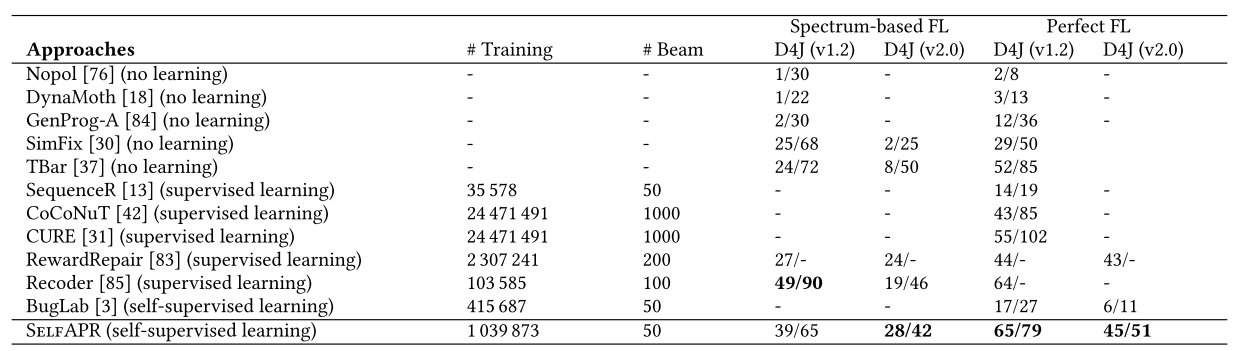
文章同时研究了以下内容:
- 修复错误和扰动规则之间的相关性:将修复的缺陷映射到基于人工分析的相应摄动规则中,14/16摄动规则至少修复了一个错误程序,显示了它们的有用性和互补性。规则的训练样本数量与相应的错误不是线性相关的。
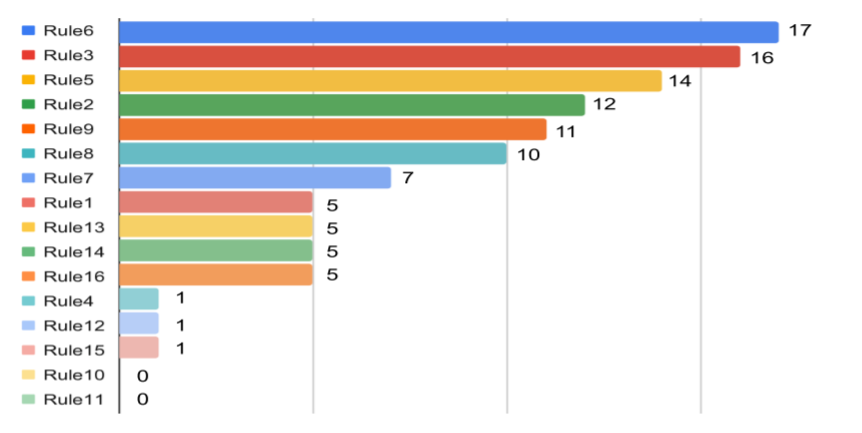
- 对比BugLab:
BugLab的范围很窄,仅限于特定的bug类型。相反,SelfAPR的摄动模型考虑了更多的规则,它们本质上是通用的。这导致了训练样本的多样性和通用性。特别是,在BugLab中不考虑代码移植和删除。这不仅减少了学习插入和学习删除的机会,而且也不能用项目特定的知识(领域类型和方法的使用)生成更多的训练样本。
RQ2:针对项目训练的必要性
下图显示了使用和不使用项目特定训练样本时selfapr的有效性。第一列给出了D4J (v1.2)的测试项目。第二列显示了在没有特定于项目的训练样本的情况下正确修复的错误数量。第三列显示了通过包含特定于项目的示例修复的错误数量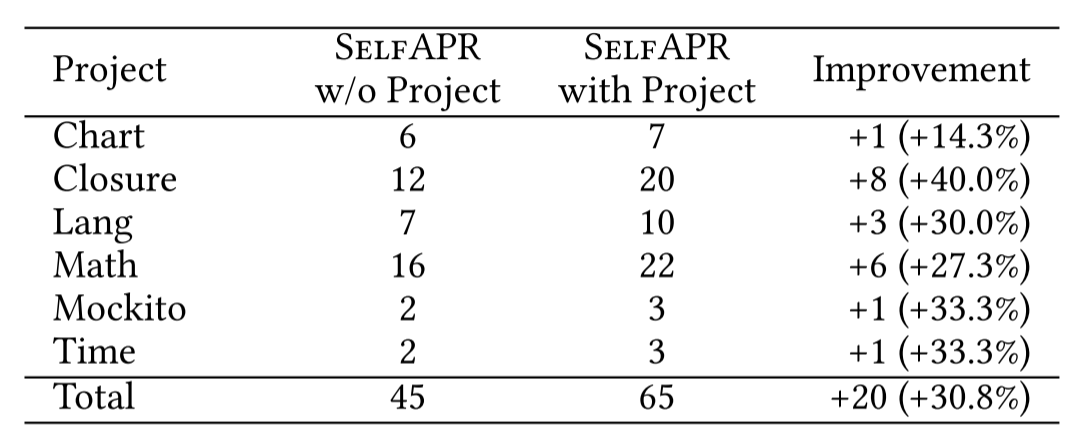
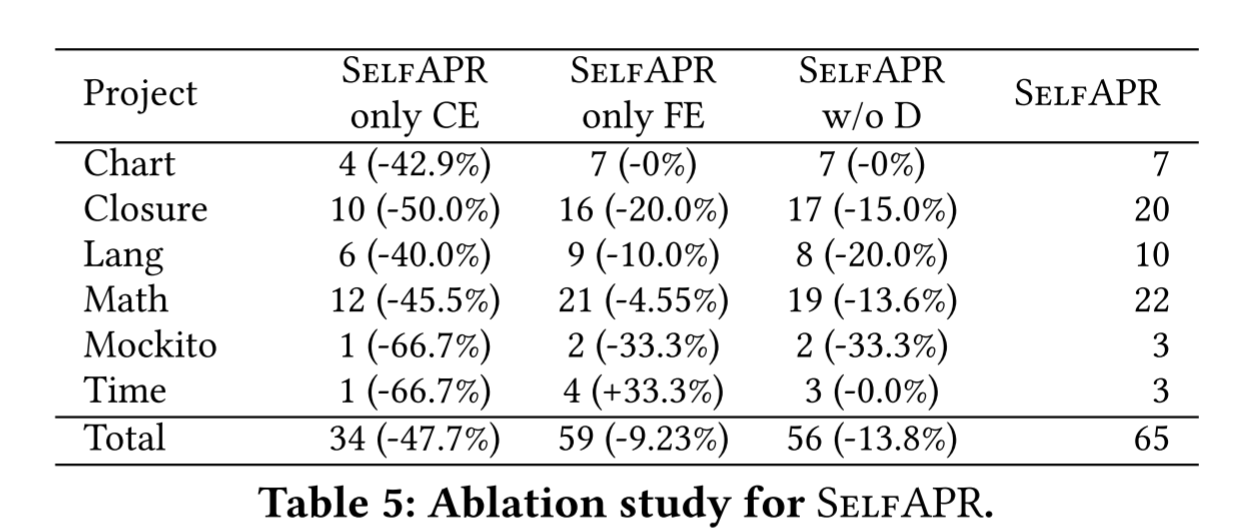
RQ3:消融
只有编译错误(CE),只有功能错误(FE),不包括诊断(SelfAPR w/o D)的训练样本上训练SelfAPR来进行消融研究。