【论文阅读】【ToSEM 25'】Giant Repair:结合大型语言模型和程序分析的混合自动程序修复
论文信息
题目:Hybrid Automated Program Repair by Combining Large Language Models and Program Analysis
链接:Tosem
主要问题
文章提出,现有的基于预定义修复模板、启发式规则和约束求解的自动程序方法难以充分利用实际应用中各种补丁的大搜索空间。其局限性在于:
- 基于LLM的APR方法直接利用生成补丁,没有进一步的优化。
LLM通常难以生成一些有关于特定程序元素的修复方案,比如局部变量和特定域方法调用等。如何利用这些不完善的修复方案来提高整体修复能力也是一个待探索的领域。 - 迄今为止,APR方法评估是在漏洞已被定位的前提下进行的。这种场景并不现实。
本文章的主要贡献在于:
- 提出GiantRepair,利用LLM输出的“并非完全正确”的补丁,从其中提取补丁骨架进行整体方法的优化;
- 在两种应用场景下进行优化评价;
- 开源: https://github.com/Feng-Jay/GiantRepair
GiantRepair
本文的核心思想是:虽然LLM生成的程序修复补丁并不一定总是正确的,但是可以给优化补丁结构提供一定的指导。因此,GiantRepair的补丁生成过程由两个主要部分组成:
- 骨架构建:从LLM生成的补丁种提取一组代码修改,通过抽象语法树的树级别差异比较有缺陷的代码和补丁代码,再使用一组抽象规则将这些修改抽象为补丁骨架;
- 补丁实例化组件:获取骨架后,通过静态分析使用有效和兼容的程序元素实例化它们,从而产生可执行的补丁。最后通过一个补丁排序策略通过运行测试用例评估补丁正确性。
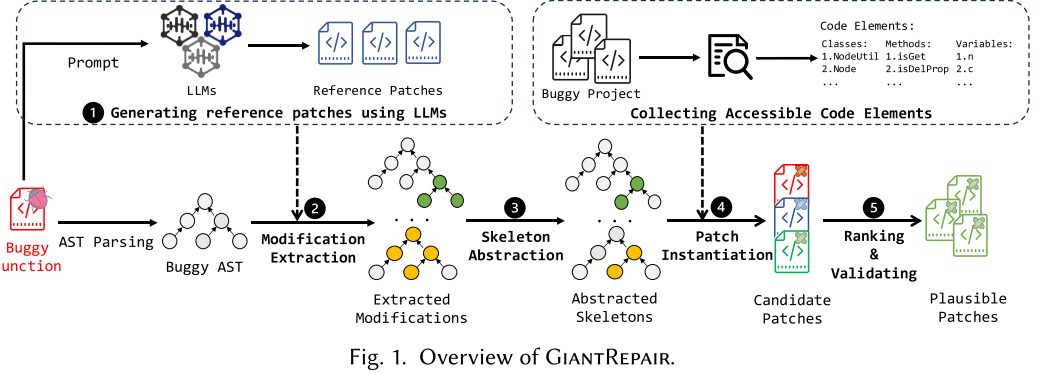
骨架构建
文章通过调研证明,并非所有LLM生成的补丁都是可以被应用的。所以,可以设计一个独立的解析器将补丁代码拆解为树形结构,以此区分bug代码和修改代码。将每个确定的修改抽象为补丁骨架。
Step1:更改抽取
目的是为匹配bug代码和修补代码中的代码元素,再为两者之间的不同生成代码修改。文章考虑语句级的代码而非表达式级,原因在于:匹配语句的效率更高,出错的可能更小;语句级的搜索空间更小。
匹配要点如下:只要两个节点的类型(AST中,例如都是if-statement)相同,则执行匹配逻辑,因此bug代码的一条语句可能有多个补丁中的匹配结果。在匹配逻辑中,进一步计算两条语句之间的相似性来保留最佳匹配,相似度计算方法如下,其中atomic stmts表示不可拆分的代码单元,ensembled stmts表示被其他语句集成的语句(比如if判断):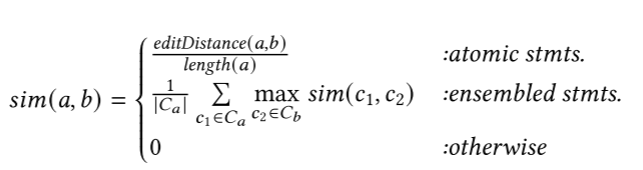
获取匹配结果后,GiantRepair可能应用以下修改:
- 更新:将语句a替换为b
- 插入:补丁语句b不匹配任何bug代码中的所有语句,但是它的父节点存在匹配关系,则在父节点之后插入b
- 删除
Step2:骨架抽取
注:这一小节的“抽象”“抽取”动词都来源于英语原文abstract及其衍生词”
如前文所述,LLM提供的补丁不一定正确,但是可以作为指导。GiantRepair设计一个代码抽取过程,也就是在Step1结束后,移除可能导致应用问题的代码元素来构建骨架,同时保留代码结构。
抽取规则如下,第一列表示抽象符号,第三列为节点示例: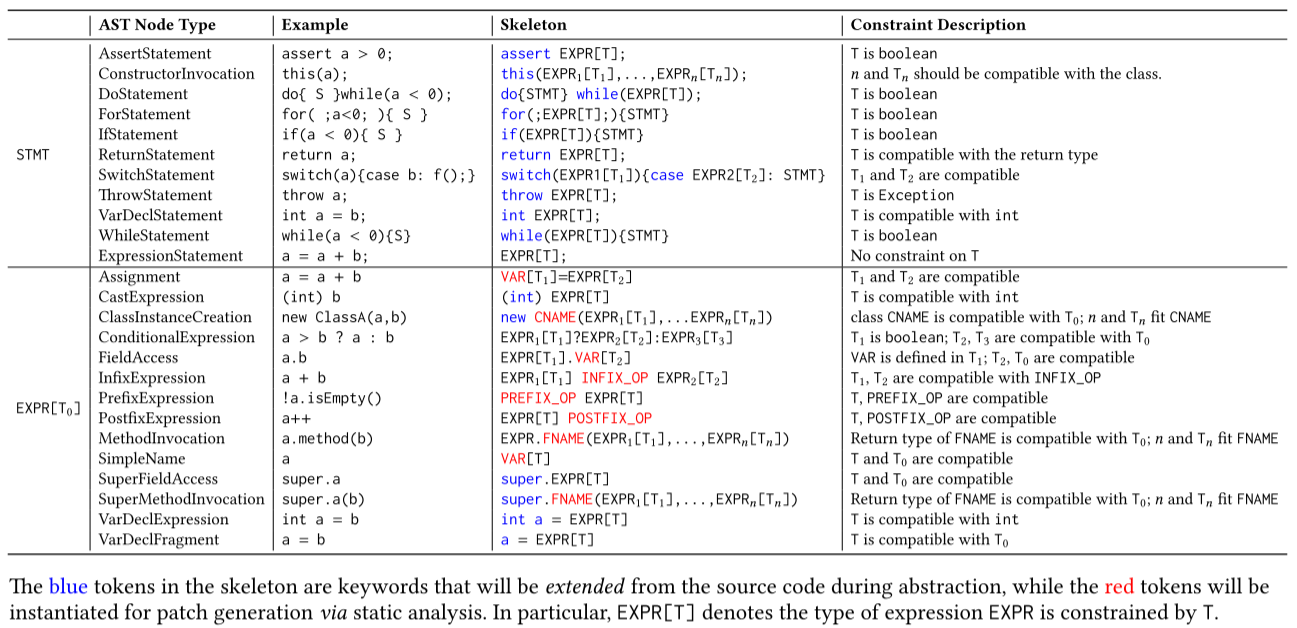
补丁实例化
根据前文所述的补丁骨架,用满足给定约束的程序元素替换其中的抽象化token。根据上图,共有四种类型的token:变量VAR、类名CNAME、函数名FNAME、操作符INFIX_OP/PREFIX_OP/POSTFIX_OP。以上骨架已经有效缩小了补丁空间,但是由于随机生成的补丁空间还是很大。为了解决这个问题,GiantRepair采取了三种策略:
- 元素选择:所有使用元素须在特定上下文可用,且满足补丁骨架的约束。对于搜索空间较少的操作符
OP,枚举所有类型兼容的元素;而对于其他类型,则使用一个静态分析过程收集可用元素:对于变量VAR,记录其类型和作用域;对于类名CNAME,记录继承关系和可访问字段;对于函数名FNAME,记录完整特征(包括参数、返回类型、所属类)。这些信息用于确保元素可用性。 - 上下文相似度:总共有两种相似度:①实例化后的补丁和bug代码之间的相似度;②实例化的补丁和LLM生成补丁之间的相似度。第一种补丁是赓续前人研究,基于现实场景下所需补丁通常只涉及小部分代码更改的前提。第二种则是基于GiantRepair的研究,它们认为LLM补丁具有指导性的价值。GiantRepair首先尽可能保留bug代码和修复补丁代码中的通用代码元素(比如变量),对于不同元素则选取与LLM生成补丁接近的补丁。具体来说应用的算法是token级的编辑距离,原因是实例化的补丁与LLM补丁共享相同的骨架,因此它们之间的主要区别主要在于变量名和函数名。
- 适应性应用:LLM生成补丁可能只有部分可应用,如果带有所有更改的补丁没有修复错误,GiantRepair自适应的应用提取修改的子集。具体来说,它在一个补丁中最多应用三个单独更改。而为了充分利用llm生成的补丁中的指导信息,GiantRepair倾向于选择最复杂的修改进行组合,因为它们可以最大限度地利用补丁中的有价值的信息。
以上三个过程旨在从给定LLM补丁中,在抽象出的骨架上生成候选补丁来约束搜索空间。
补丁排名和验证
给定一组由llm生成的候选补丁时,GiantRepair倾向于那些能够为补丁生成提供更多新资源的候选补丁。通过这种方式,我们可以通过最大化可用于生成有效修复的修复相关信息来最好地利用llm的代码生成能力。具体来说,评估插入、更新修改的数量(这些修改次数越多,补丁等级越高)。
最后应用实例化后的补丁,输入用例,全部通过则证明是有效补丁。
实验
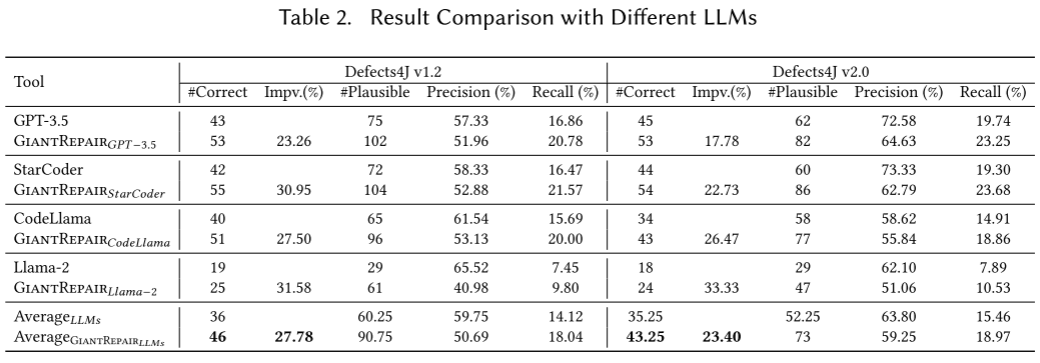
- 对于采用不同LLM的对比:
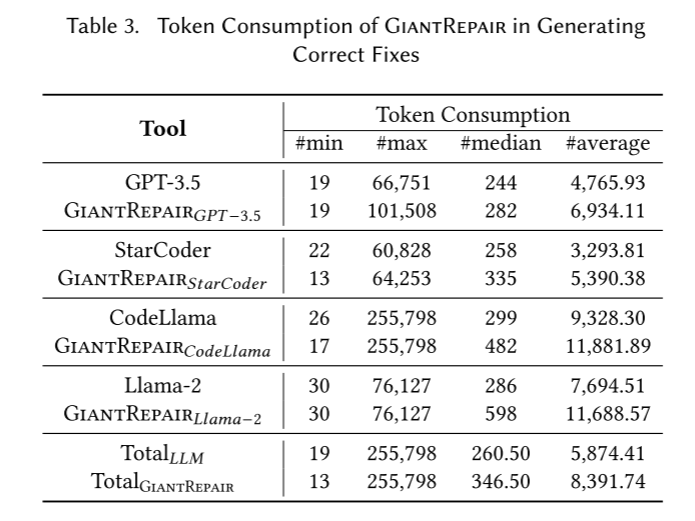
- token消耗记录
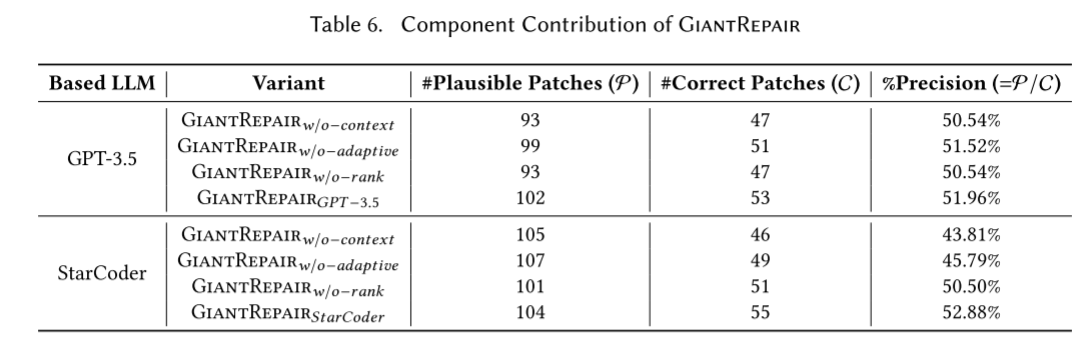
- 消融