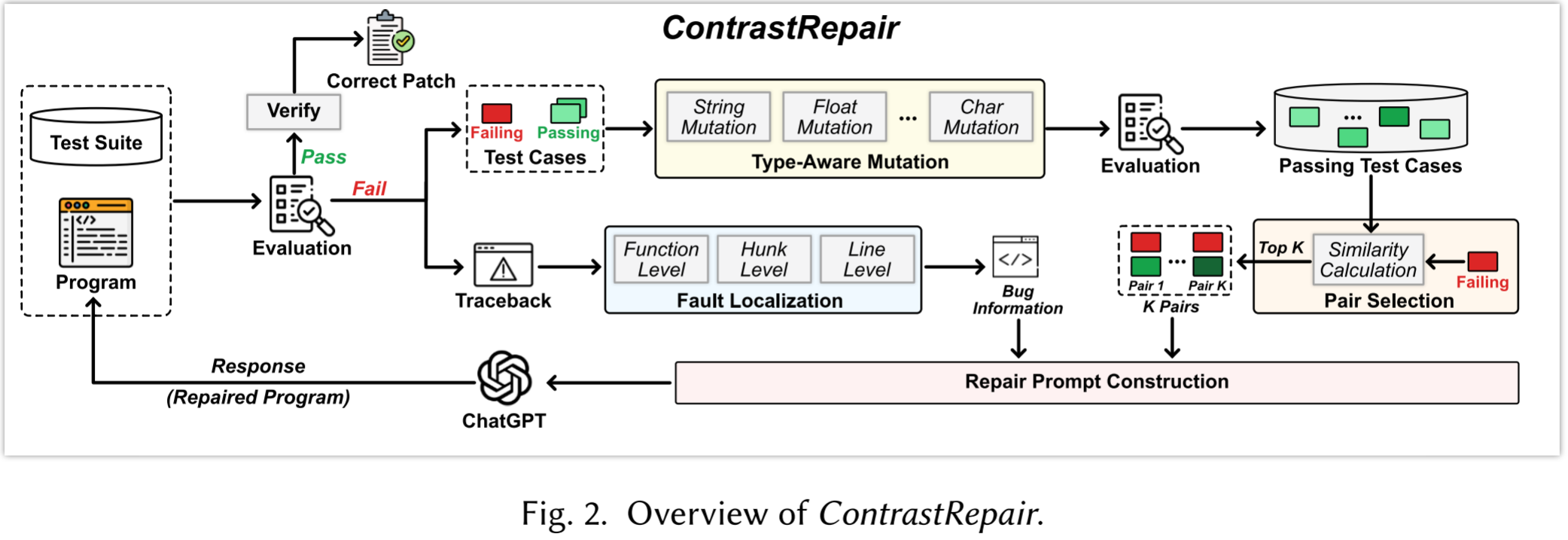
【论文阅读】【NeurIPS 24'】MAGIS:多智能体支撑的大语言模型Github问题解决——通过精心设计的智能体协作来增强问题解决能力
论文信息:
- 题目:MAGIS: LLM-Based Multi-Agent Framework for GitHub Issue ReSolution
- 链接:NeurIPS 24’
主要问题
类似Github的代码托管平台,其项目通常不是一成不变的,开源软件作者会更新多个版本,并将源码按照版本号推至代码仓,本文的根本目的是解决开源代码产生的各类“issue”,同时研究了多智能体应用对该下游任务的优化性能。本文的主要贡献如下:
- 我们对llm解决GitHub问题进行了实证分析,探讨了定位代码文件/行、代码变更的复杂性与解决成功率之间的相关性。
- 我们提出了一种新的
基于llm的多智能体框架MAGIS,以减轻现有llm在GitHub问题解决上的局限性。我们设计的四类代理及其在规划和编码方面的协作都释放了llm在存储库级别编码任务上的潜力。 - 我们在SWE-bench数据集上比较了我们的框架和其他强大的大语言模型竞争对手(即GPT-3.5, GPT-4和Claude-2)。结果表明,MAGIS显著优于这些竞争对手。进一步的分析证实了框架设计的有效性和必要性。
特别地,文章的实证研究列出了使用大语言模型的三个局限:
- 定位问题文件:代码仓库中的源代码通常不只涉及单个文件,如何定位存在问题的代码文件?
- 定位问题代码行
- 代码变化的复杂度:如何量化这个指标?
MAGIS
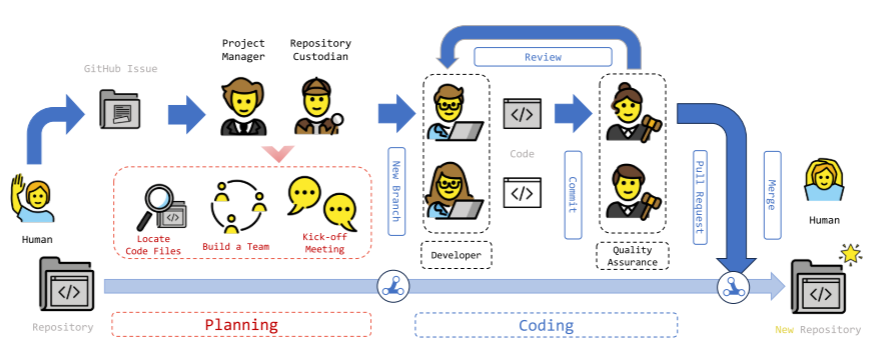
智能体设置
- 经理(Manager):根据预先组成的团队将问题分解为任务,并将这些任务分配给具有不同技能的成员。
- 代码仓管家(Repository Custodian):定位与问题相关的文件。针对这个任务,LLM智能体的局限在于输入内容的长度。
- 开发者(Developer):将代码修改过程分解为包括代码生成在内的子操作。
- QA工程师:代码审查,保证质量。
智能体协同过程
前置过程
前置过程由经历、管家和开发者参与,被分为三个阶段:定位文件->团队建设->会议。
- 定位文件【管家】
首先,根据BM25算法寻找出仓库中与问题查询最相关的k个文件,然后在这k个文件的各个版本中进一步查找。为了解决大模型在这k个相关文件中的重复比较问题,MAGIS设计了一种内存优化算法:首先使用大模型将文件某个版本fi表示为摘要si,摘要比整个文件短。在对比fi的最新版本fh时,大模型只需要根据fh和Δd即可理解fi。尤其是,当fi的内容很长时,这一点很有用。 - 团队建设【经理】
经理智能体的工作是根据问题的需要确定团队成员。输入一个上一步确定的问题文件集,将其中的每个文件以及问题描述交由大模型将问题转换为文件级的任务。然后,再根据人物集和文件确定开发者(Developer)的个性化任务。这种个性化任务的设计简化了问题解决流程,因为每个成员只需要专注于解决单个任务 - 会议【经理+开发者】
两个目的:①.确定经历的任务是否合理,确定团队中所有开发者可以协作解决问题;②.确定任务的并发和排序问题。会议采取循环发言的机制,经理负责引导和总结。
编码【开发者+QA工程师】
根据先前实证研究的成果,MAGIS将代码变更生成拆解为多步编码过程,旨在放大代码生成方向的优点,缓解代码变更生成的弱点。根据每个先前确定的任务和与其相关的代码文件,开发者通过大模型生成QA工程师的角色描述,然后二者合作:
首先,开发者需要确定修改的代码文件行号范围(si,ei),通过大模型分析任务内容和文件内容,生成决策。这些间隔将文件分割为修改部分和保留部分。然后,开发者生成新的代码片段替换修改部分,得到新版本的代码文件。再利用git工具计算新生成文件和原始文件的变更Δd。有了Δd,QA工程师依托大模型生成review_comment和review_decision。若决策否定,则反馈开发者修改,直到决策为真为止。迭代最后,Δd是固定的。
实验
实验数据集采用了SWE-bench完成,基础大模型使用了GPT-4。结果如下:
整体效率评估
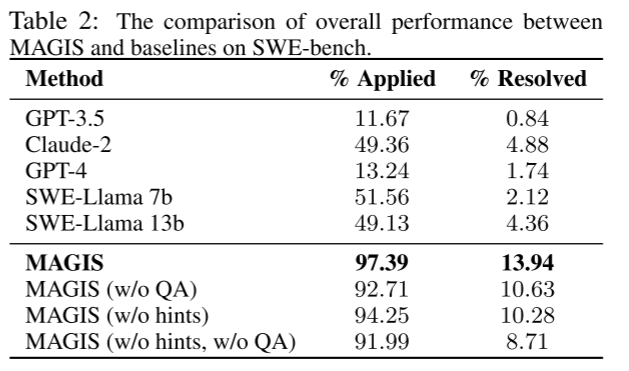
其中消融实验模拟两组情况:
- 没有QA工程师。
- 没有提示,也就是没有pull请求时的注释部分。
前置阶段效率评估
分析代码仓管家和经理智能体的性能。前者的性能可用召回率和文件数的关系曲线中观察,我们的方法在不同数量的选定文件中始终优于BM25基线,表明我们的方法可以用最小的选择确定相关代码文件的最大数量: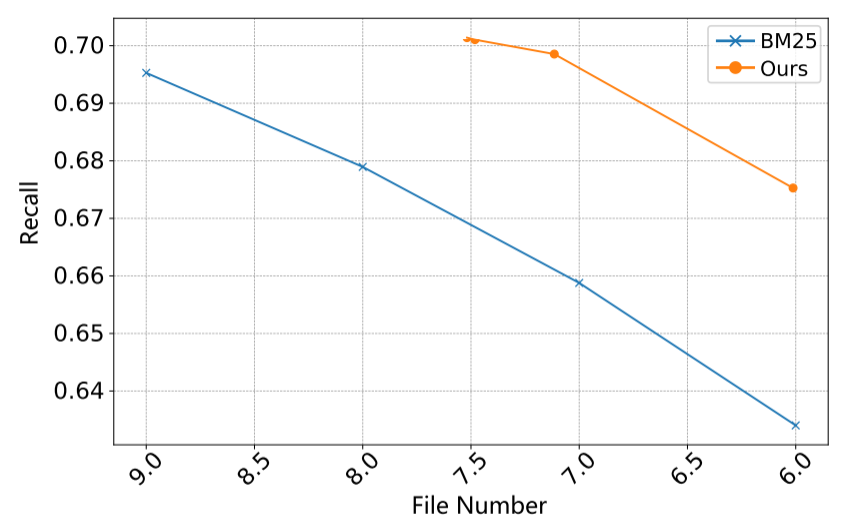
对于后者,MAGIS检查了其生成的任务描述与LLM的参考代码更改的一致性,基于GPT4作为评估器,对参考代码变更与生成的任务描述之间的相关性进行评分,下图展示的是生成的任务描述和参考代码变更之间的相关分数的分布,大多数得分在3分或以上,这意味着大多数任务描述在规划方面是正确的。
编码阶段效率评估
主要评估开发者在定位问题行和解决不同复杂度问题上的能力。
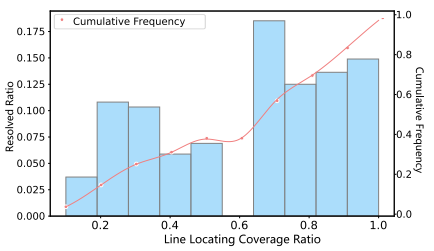
下图评估的是MAGIS和不同基线间行定位覆盖率的差别。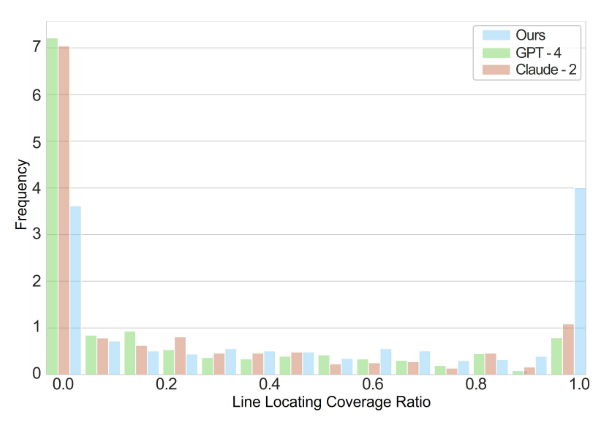
进一步,下图评估行定位覆盖率和问题解决率之间的关系。右侧的4个柱高于左侧的5个柱,这表明随着线定位覆盖率的增加,解决率会增加。